Abstract
Emotion estimation in images is a challenging task,
typically using computer vision methods to directly estimate
people’s emotions using face, body pose and contextual cues. In
this paper, we explore whether Large Language Models (LLMs)
can support the contextual emotion estimation task, by first
captioning images, then using an LLM for inference. First, we
must understand: how well do LLMs perceive human emotions?
And which parts of the information enable them to determine
emotions? One initial challenge is to construct a caption that
describes a person within a scene with information relevant
for emotion perception. Towards this goal, we propose a set of
natural language descriptors for faces, bodies, interactions, and
environments. We use them to manually generate captions and
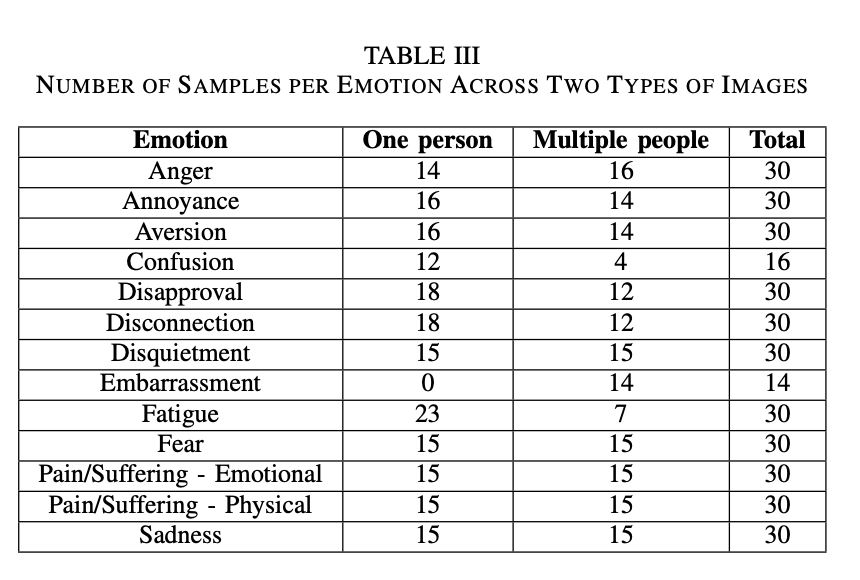
emotion annotations for a subset of 331 images from the EMOTIC
dataset. These captions offer an interpretable representation for
emotion estimation, towards understanding how elements of a
scene affect emotion perception in LLMs and beyond. Secondly,
we test the capability of a large language model to infer an
emotion from the resulting image captions. We find that GPT-
3.5, specifically the text-davinci-003 model, provides surprisingly
reasonable emotion predictions consistent with human annota-
tions, but accuracy can depend on the emotion concept. Overall,
the results suggest promise in the image captioning and LLM
approach.
Approach
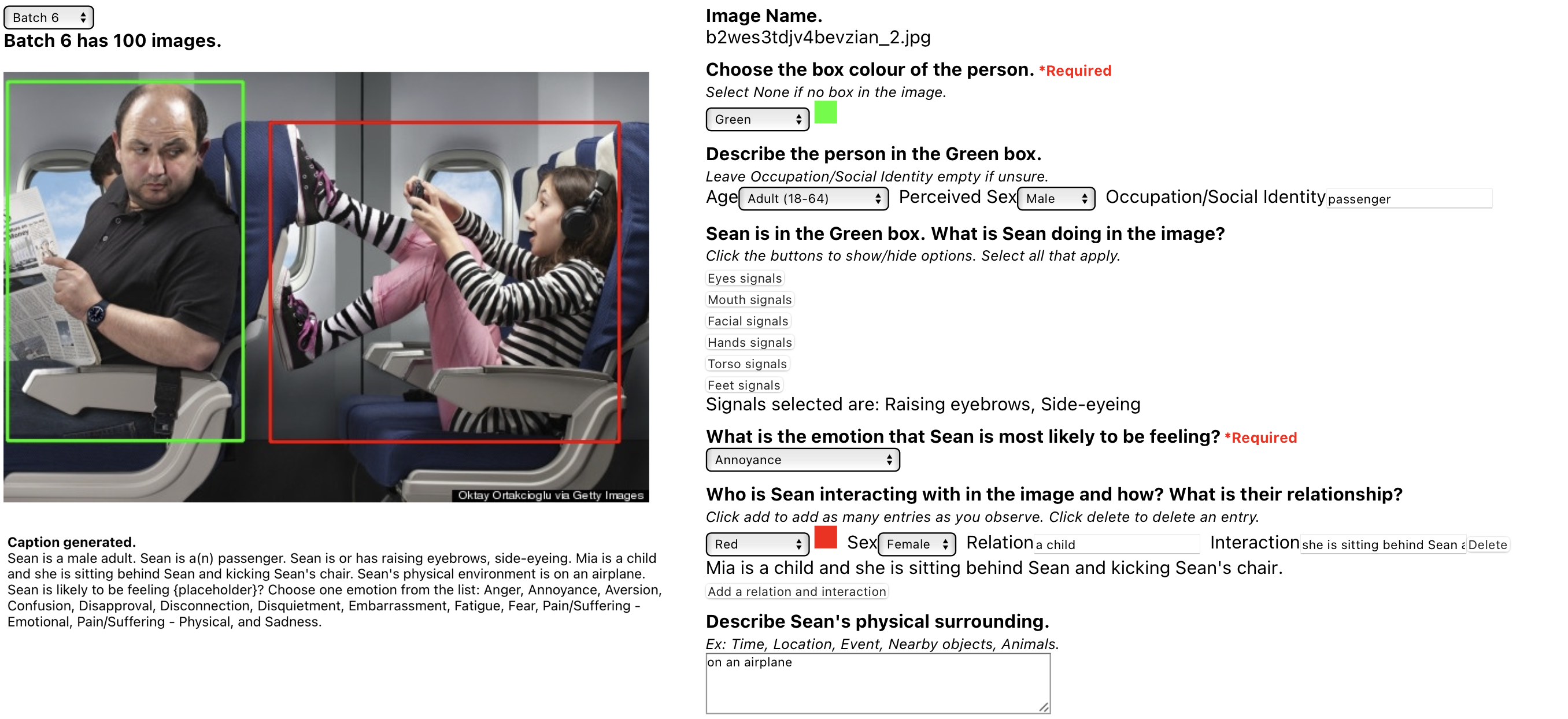
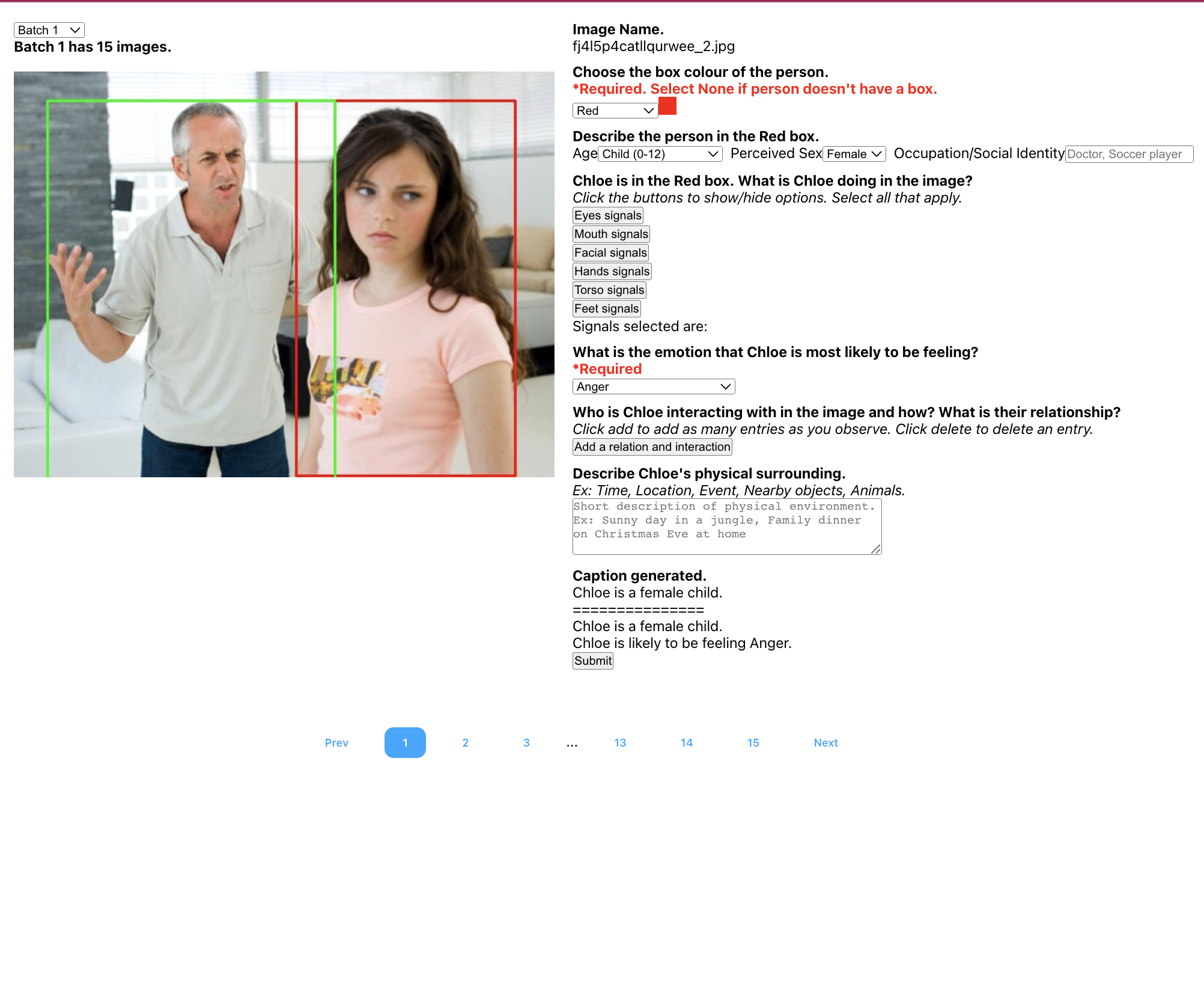
Image Annotations

Generated Captions
Samples
Once the annotations were complete, GPT-3.5 was used
to predict emotion labels with the help of a prompt. The
prompt was structured to elicit single emotion prediction when
presented with an image annotation.
The prompt was as follows: ”Sean is a male adult. Sean is a(n) passenger. Sean
is or has raising eyebrows, side-eyeing. Mia is a child and
she is sitting behind Sean and kicking Sean’s chair. Sean’s
physical environment is on an airplane. Sean is likely feeling
a high level of {placeholder}? Choose one emotion from
the list: Anger, Annoyance, Aversion, Confusion, Disapproval,
Disconnection, Disquietment, Embarrassment, Fatigue, Fear,
Pain/Suffering (emotional), Pain/Suffering (physical), and Sadness.”
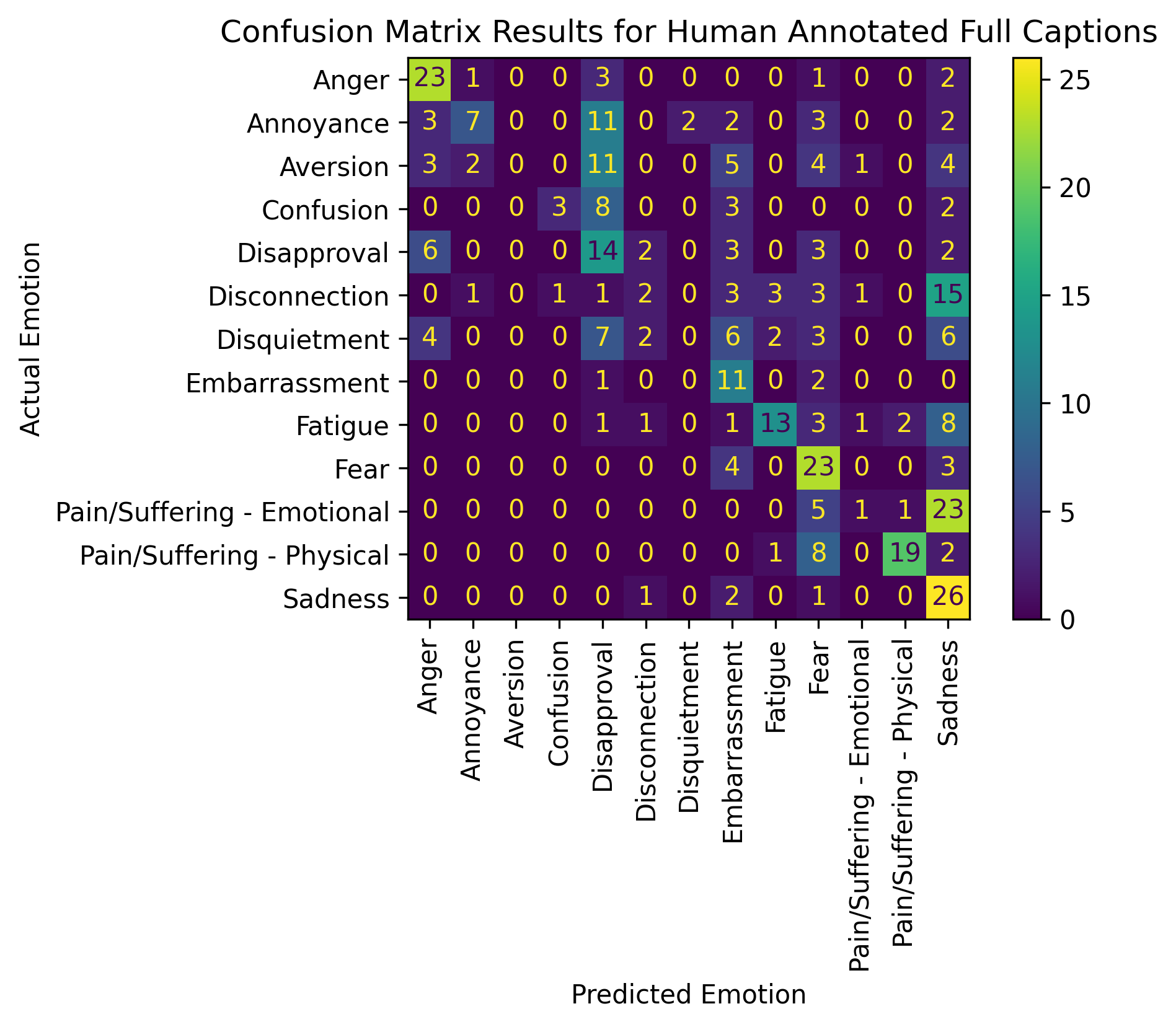
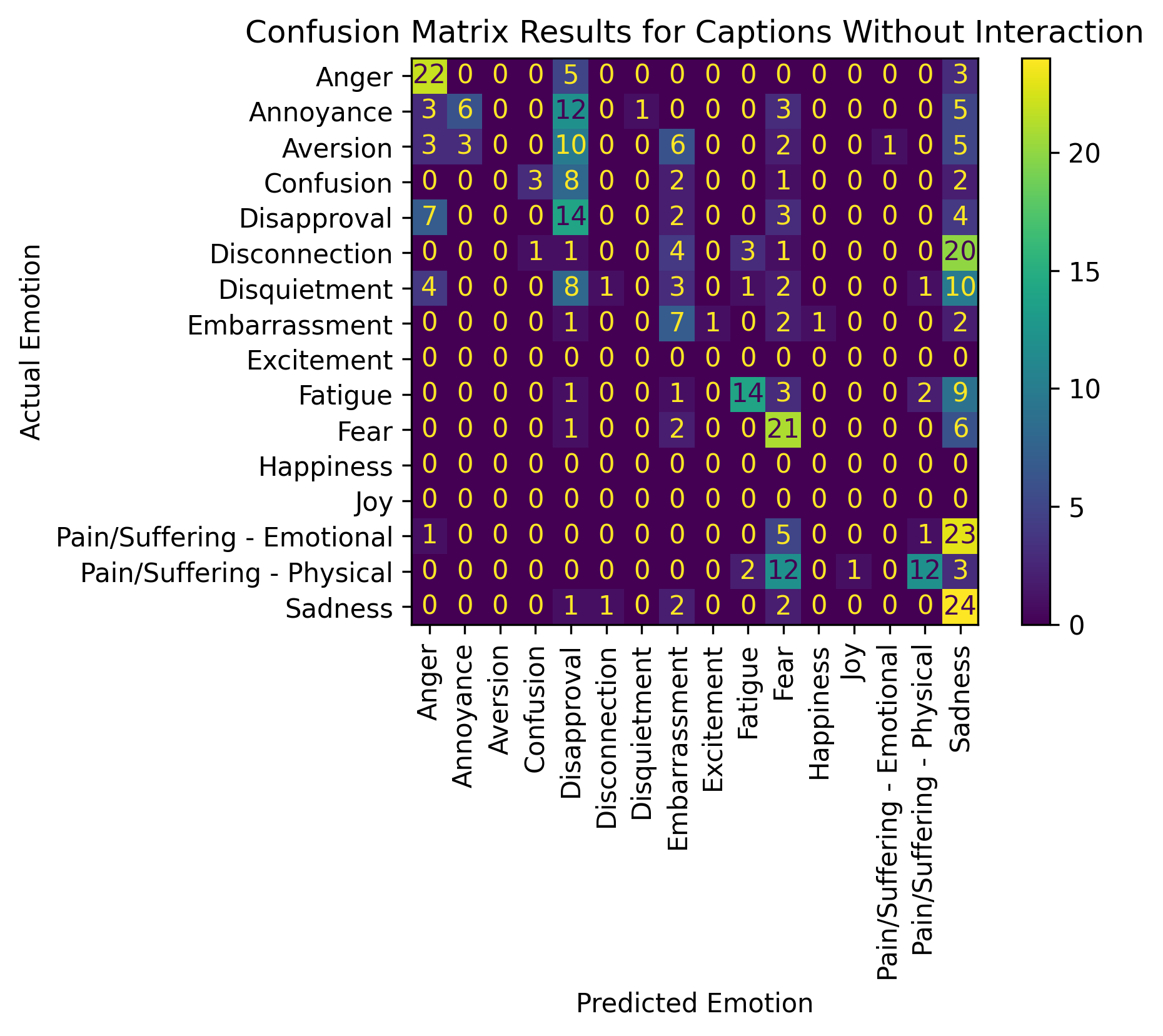
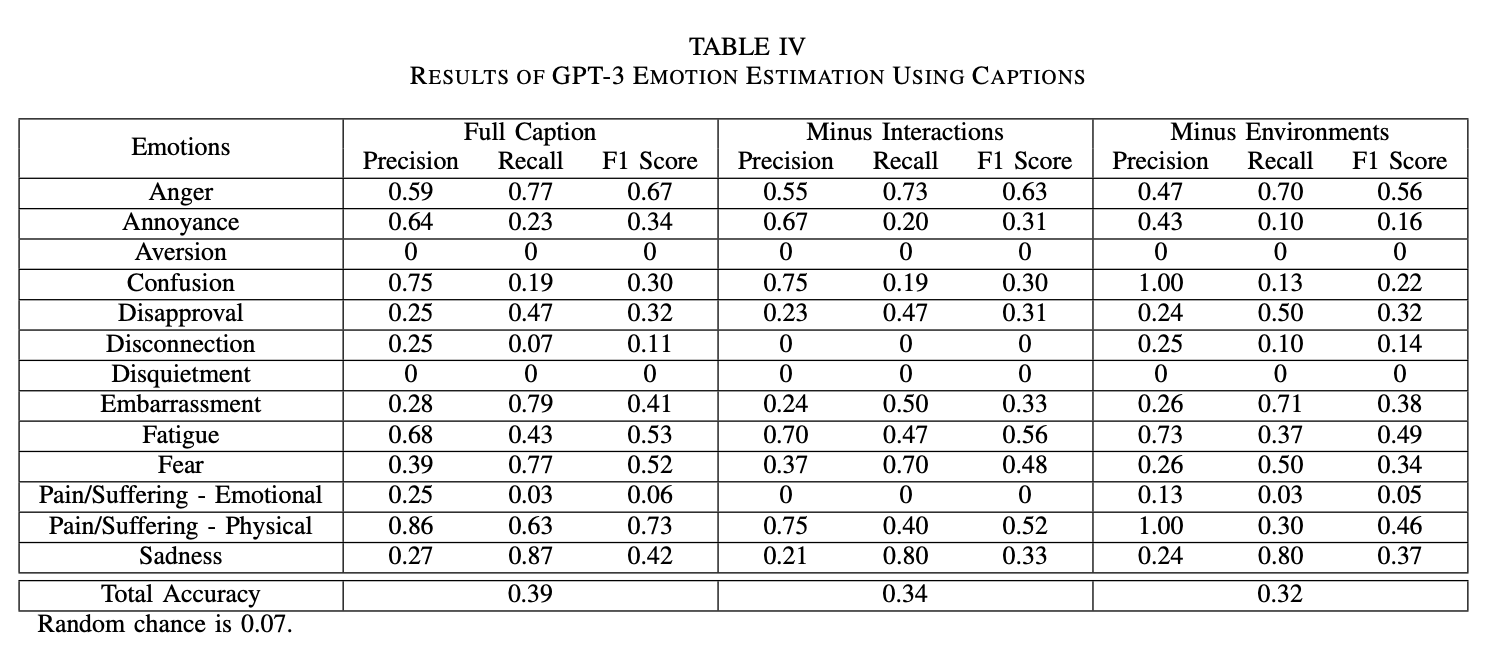
To evaluate the performance of the models, we compared
the LLM’s predictions to the ground truth of the images established by the annotators
Results
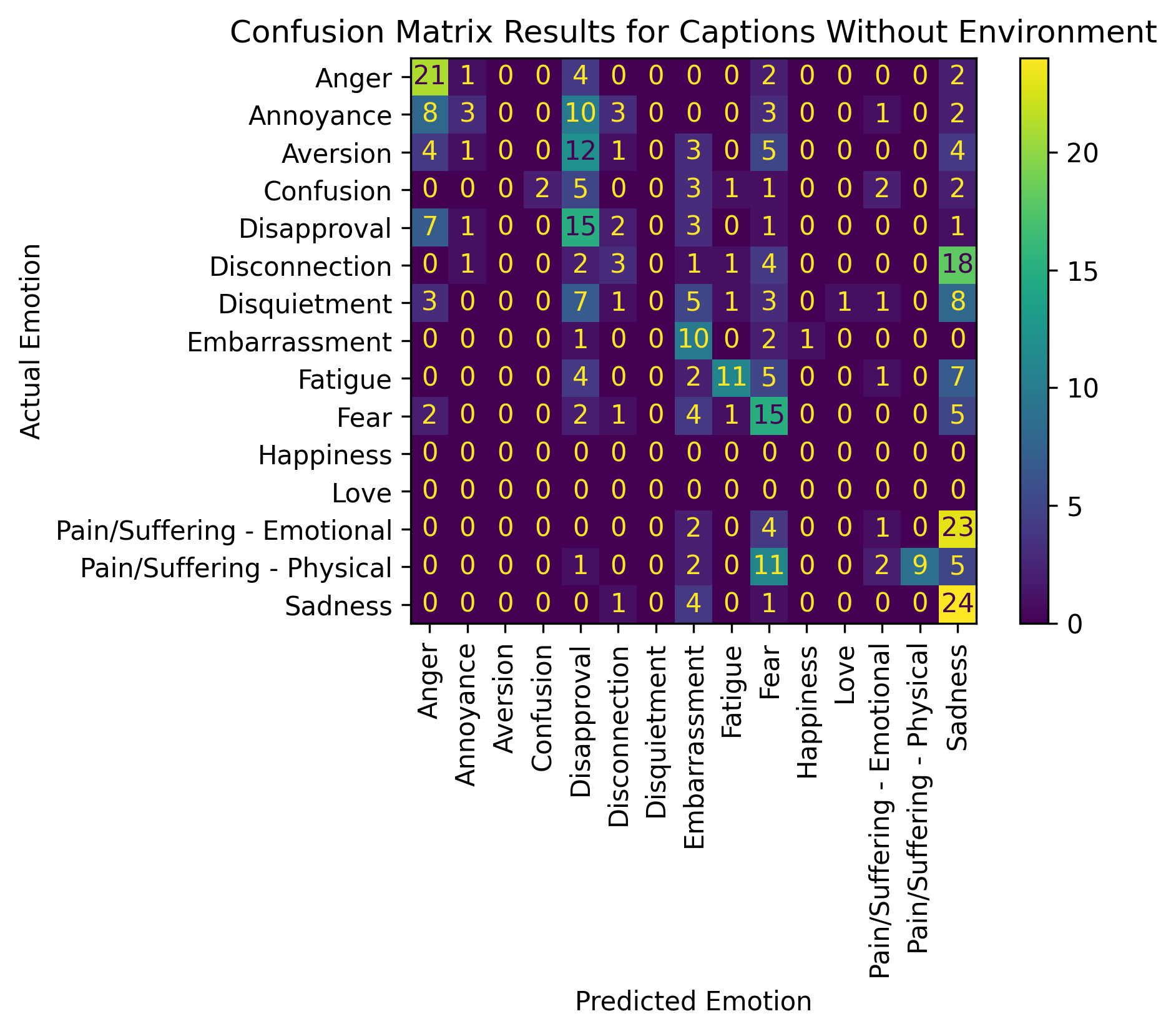
GPT-3.5 Results
Visual Results (More visual results can be found here)

Ground Truth: Fear
GPT-3.5 Prompting
Full Caption: Chloe is a female adult. Chloe is or has frowning, open mouth. Chloe’s physical environment is right in front of an alien hand in the dark. Chloe is likely feeling...?
GPT Prediction: Fear
Minus Interactions: Chloe is a female adult. Chloe is or has frowning, open mouth. Chloe's physical environment is right in front of an alien hand in the dark. Chloe is likely feeling...?
GPT Prediction: Fear
Minus Environment: Chloe is a female adult. Chloe is or has frowning, open mouth. Chloe is likely feeling....?
GPT Prediction: Disapproval
Notable Observation: Fear is an emotion that may benefit from environmental context. The F1 score for this image dropped from 0.52 and 0.48 with
environments to 0.34 without environments, i.e, when "right in front of an alien hand in
the dark" was removed from the full caption of this image, the predicted emotion changed
from Fear to Disapproval.

Ground Truth: Embarrassment
GPT-3.5 Prompting
Full Caption: Lucas is a male adult. Lucas is a(n) groom. Lucas is or has lips that flatten, palms open. Mia is Lucas’ bride and she is smiling. Lucas’ physical environment is cake falling down
at wedding. Lucas is likely feeling....?
GPT Prediction: Embarrassment
Minus Interactions: Lucas is a male adult. Lucas is a(n) groom. Lucas is or has lips that flatten, palms open. Lucas's physical environment is cake falling down at wedding. Lucas is likely feeling....?
GPT Prediction: Embarrassment
Minus Environment: Lucas is a male adult. Lucas is a(n) groom. Lucas is or has lips that flatten, palms open. Mia is Lucas' bride and she is smiling. Lucas is likely feeling....?
GPT Prediction: Happiness
Notable Observation: When the environment was removed from the following image's caption, Happiness, a positive emotion, was predicted which was not on the list of
13 negative emotions that we provided to GPT-3.5 to choose from.

Ground Truth: Embarrassment
GPT-3.5 Prompting
Full Caption: Jack is a male adult. Jack is or has smiling. Beth is a customer and she is side-eyeing Jack. Zoe is a customer and she is staring at Jack. Jack's physical environment is eating in a movie theatre.
Jack is likely feeling....?
GPT Prediction: Embarrassment
Minus Interactions: Jack is a male adult. Jack is or has smiling. Jack's physical environment is eating in a movie theatre. Jack is likely feeling....?
GPT Prediction: Happiness
Minus Environment: Jack is a male adult. Jack is or has smiling. Beth is a customer and she is side-eyeing Jack. Zoe is a customer and she is staring at Jack. Jack is likely feeling....?
GPT Prediction: Embarrassment
Notable Observation: When the interactions were removed from the following image's caption, Happiness, a positive emotion, was predicted which was not on the list of
13 negative emotions that we provided to GPT-3.5 to choose from.
Resources
Paper

Annotation Website
BibTeX
If you find this work useful for your research, please cite:
@inproceedings{yang2023contextual,
title={Contextual Emotion Estimation from Image Captions},
author={Yang, Vera AND Srivastava, Archita AND Etesam, Yasaman AND Zhang, Shay AND Lim, Angelica},
booktitle={International Conference on Affective Computing and Intelligent Interaction (ACII)},
year={2023},
}